GitLab 시스템 장애 감지와 서비스 복구
지난 일요일에 GitLab 시스템 장애가 발생하여 서비스를 복구하는 일이 있었습니다. 시스템 장애 감지부터 서비스 복구까지의 경험을 공유하고 향후 운영 계획에 대해서 알려드리고자 합니다.
GitLab 시스템 장애 감지
GitLab 서버 및 서비스 모니터링 알람
GitLab 서버는 monit 모니터링 도구를 이용하여 서버 자원(CPU, 메모리)과 프로세스(nginx, postgresql), GitLab 서비스 헬스체크 등을 모니터링하고 이상 징후 발생 시에 이메일을 통해 알림을 받고 있음
지난 일요일(4월16일) 오전부터 지속적으로 CPU 사용률이 기준치를 초과하고 그 영향에 따라 서비스 헬스체크 Fail 알람이 지속적으로 발생
CPU 과부하 상태 감지
top를 이용해 CPU를 확인한 결과 CPU I/O WAIT 증가로 인해 CPU 과부하 상태가 발생하고 있음
top - 10:10:13 up 378 days, 19:26, 2 users, load average: 4.68, 4.53, 4.66 Tasks: 212 total, 1 running, 211 sleeping, 0 stopped, 0 zombie Cpu(s): 0.5%us, 0.4%sy, 0.0%ni, 35.4%id, 63.6%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 16125552k total, 15843336k used, 282216k free, 353176k buffers Swap: 8134652k total, 374668k used, 7759984k free, 10525700k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 17766 git 20 0 1231m 866m 4264 S 1.0 5.5 155:15.46 bundle 17759 gitlab-r 20 0 44968 7008 1264 S 0.6 0.0 73:01.74 redis-server 304 root 20 0 0 0 0 S 0.2 0.0 0:32.61 scsi_eh_0 17736 gitlab-w 20 0 52884 5236 1980 S 0.2 0.0 11:53.23 nginx 17757 gitlab-p 20 0 4078m 1792 1164 S 0.1 0.0 0:23.51 postgres 17829 git 20 0 664m 447m 4340 S 0.1 2.8 17:44.75 bundle 31805 root 20 0 136m 1332 988 S 0.1 0.0 0:00.02 crond 31814 root 20 0 62056 3812 2960 S 0.1 0.0 0:00.02 ssh 55 root 20 0 0 0 0 S 0.1 0.0 0:03.85 ata_sff/1 1824 git 20 0 566m 335m 4104 S 0.1 2.1 4:39.14 bundle
높은 CPU 사용률 :
load average: 4.68, 4.53, 4.66그러나, 프로세스 중에 CPU를 과다 점유하는 프로세스는 발견되지 않음 CPU I/O WAIT 증가로 인한 CPU 점유율 높아지는 현상 :63.6%wa
디스크 배드 블럭 발견
badblocks를 이용해 디스크 배드 블럭을 체크한 결과 10개의 배드 블럭이 발견
[root@gitlab ~]# badblocks -v /dev/mapper/vg_gitlab-lv_root Checking blocks 0 to 52428799 Checking for bad blocks (read-only test): 18874368done, 4:21 elapsed 18874424done, 5:13 elapsed 18874425done, 5:31 elapsed 18874426done, 5:48 elapsed 18874427done, 6:06 elapsed 19478704done, 6:32 elapsed 19478756done, 7:07 elapsed 19478757done, 7:24 elapsed 19478758done, 7:42 elapsed 19478759done, 7:59 elapsed done Pass completed, 10 bad blocks found.
다른 도구 설치를 위해 yum을 실행했으나 repository용 데이터베이스가 깨졌다는 오류 발생
서비스 복구를 위한 시스템 이전
파일 시스템(디스크)이 정상적이지 않은 상태이고 일요일이라 지원을 받기 어려운 상황이라 시스템 복구 보다는 다른 대체 서버로 서비스를 이전하는 방법을 선택함
시스템 이전 절차
- 표준화실 개발서버에 GitLab 설치
- Daily 백업한 파일로 데이터 복구
- 이전한 서버로 GitLab 도메인 정보 변경 및 443 포트에 대한 방화벽 설정 (기술연구소 한동헌 주임)
- 모니터링, 백업 및 기타 유지보수 기능 설정
- 최종 서비스 체크
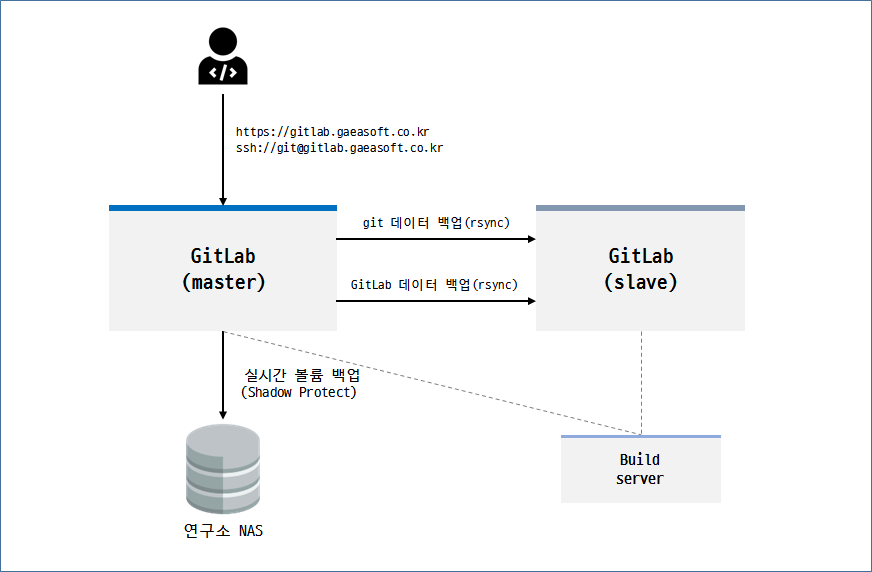
안정적인 서비스를 위한 향후 계획
GitLab은 회사의 중요한 자산이자 업무 인프라로 시스템의 안정성과 가용성이 중요하여 기존 PC급 시스템에서 서버급 시스템으로 구축하고 데이터 안정성을 위한 RAID 구성과 백업솔루션 적용. 기존 시스템은 문제가 되는 디스크를 교체하여 GitLab 백업 및 슬레이브 용도로 사용
GitLab 신규 시스템 구축
| 구성 | 내역 | 비고 |
|---|---|---|
| 모델 | 1U 슈퍼마이크로 리던던트 서버 | - |
| CPU | E5-2620 v4 (20M Cache, 2.10 GHz) 8core | - |
| Memory | DDR4 16GB | - |
| HDD | 2TB SATA3 7,200Rpm Enterprise | 2EA, RAID 구성 |
| 백업솔루션 | ShadowProtect | https://www.storagecraft.com/ |
GitLab 신규 시스템 백업 구성